
HashMap
HashMap
해싱(Hashing)된 맵(Map). 해싱을 사용하여 많은 양의 데이터를 검색하는데 있어 뛰어난 성능을 가진다.
인터페이스 Map을 구현하고 있어 키(Key)와 값(Value)로 구성된 Entry 객체를 저장하는 구조를 가진 자료구조이다.
맵은 키의 중복은 허용하지 않지만 값은 중복이 되어도 상관없다.
Hashing이란?
해시함수를 사용하여 해시 테이블에 저장하고 검색하는 기법이다.
해싱은 키에 산술적인 연산을 적용하여 항목이 저장되어 있는 테이블의 주소를 계산하여 항목에 접근한다.
해싱은 O(1)의 시간복잡도 안에서 탐색을 할 수 있다. 해싱은 사전이라는 프로그램을 만들때 효율적일 수 있다.
자료구조 중에서는 대표적으로 HashMap이 있다.
해싱의 구조
무언가의 데이터들을 보관할 떄 배열에 필요한 크기를 생성하여 인덱스를 외워두고 필요한 정보를 찾아쓰면 되지만 데이터가 무한정 많아지면 모두 외우기란 불가능한 일이다.
해시테이블
키와 값으로 이루어진 자료주고이다. 대표적으로 HashMap이 있는데 이러한 자료구조는 해시테이블을 이용한다.
해시 함수
무언가에 대해서 인덱스로 두고 주소의 번지처럼 정수로 사용한다면 데이터를 찾을 떄 그 주소로 찾아가서 필요한 데이터를 바로 확인할 수 있는 것이 해싱의 기법이다.
이떄, 키를 인덱스로 변환하는 것이 해시함수이다.
버킷
각각의 Key에 해시함수를 적용해 고유한 index를 생성하고, 이를 이용하여 값을 저장하거나 검색하게 된다. 여기서 실제 값이 저장되는 공간을 버킷이라 한다.
동작원리
HashMap은 키에 대한 해시 값을 사용하여 값을 저장하고 조회하여 동적으로 크기가 증가하는 연관배열(associate array)이다.
💡 associate array: 키 하나와 값 하나가 연관되어 있으며 키를 통해 연관되는 값을 얻을 수 있는 자료구조
어떠한 두 객체가 X.equals(Y)가 ‘거짓’이고 두 해시코드가 같지 않다면 이때 사용하는 해시 함수는 완전한 해시 함수(perfect hash functions)라고 한다.
기본자료형은 완전한 해시 함수로 구현할 수 있지만 String, POJO(Plain old java object)는 사실상 불가능하다.
HashMap은 버킷의 위치를 정할 때 객체의 해시코드를 사용한다. 이 때 해시코드의 결과 자료형은 int인데, 32비트 정수 자료형(int)으로는 완전한 자료 해시 함수를 만들 수 없다.
논리적으로 2^32보다 더 많은 객체를 생성할 수 있기 때문이다. 설령 가능하여도 그 만큼의 데이터를 생성하는 것은 엄청난 메모리 낭비이며 배열을 사용하는 것과 다르지 않아 의미가 없다.
따라서 메모리를 절약하기 위해 표현해야 할 N의 범위보다 적은 M만큼의 배열을 사용한다. (예를들어 총 50개의 정수를 가지고 해시자료 구조를 사용하면 버킷을 15개 정도 사용하는 것이다.)
int index = X.hashCode() % M;
HashMap은 객체의 hashCode() 메서드의 반환 값을 사용한 hashCode() % BUCKET_SIZE 수식을 사용하여 데이터를 저장/조회를 할 버킷 위치를 계산한다. 위 수식을 사용하여 데이터를 BUCKET_SIZE 내의 위치에 값을 저장할 수 있게 된다.
동작 과정 정리
hashCode()를 통해 해시코드가 생성이 되면 해당 index에 위치한 버킷의 위치로 간다. 이때 버킷이란 데이터를 저장하는 단위로 여러개의 데이터들이 있다. 이 버킷에서 equals()를 이용하여 버킷안의 데이터들 중에서 찾고자 하는 데이터를 찾는것이다.
데이터들은 최초 List의 구조로 되어있으며 size가 8이 넘을때 Tree 구조로 변경된다.
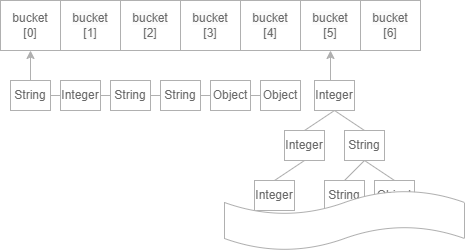
해시 값 충돌시?
그럼 데이터는 무한에 가깝다 보니 결국 해시의 충돌이 일어날 수 있는데 이떄 해결하기 위한 대표적인 두가지 방법이 있다.
- 개방 주소법(Open Addressing)
- 분리 연결법(Seperate Chaining)
개방 주소법(Open Addressing)
추가적인 메모리를 사용하는 Chaining 방식과 다르게 비어있는 해시 테이블의 공간을 활용하는 방법이다.
- Linear Probing: 만약 h[k]에서 충돌이 일어난다면 h[k + 1]이 비어있는지 확인 후 비어있지 않다면 h[k + 2]… 식으로 계속 확인하는 방법이다.
- Quadratic Probing: 해시의 저장순서 폭을 제곱으로 저장하는 방식이다. 예를들어 처음 충돌이 발생하는 경우 1만큼 이동하고 그 다음 계속 충돌이 일어나면 2^2, 3^2 칸씩 옮기는 방법이다.
- Double Hashing Probing: 해시된 값을 한번 더 해싱하여 새로운 주소를 할당하기 때문에 다른 방법보다 많은 연산을 한다.
분리 연결법(Seperate Chaining)
Java HashMap에서 사용하는 방법이다. Seperate Chaining이란 동일한 버킷 데이터에 대해 List or Tree 자료구조를 이용해서 추가 메모리를 사용하여 다음 데이터의 주소를 저장하는 방식이다.
그리고 충돌이 많이 발생하여 리스트의 형태로 계속 쌓이게 되면 검색하는데 시간복잡도가 O(n)으로 나빠지게 된다. 그래서 Java8의 HashMap은 리스트의 개수가 8개 이상이 되면 Self-Balancing Binary Search Tree 자료구조를 사용해 Chaining 방식을 구현한다.(탐색할 때 O(logN)으로 성능이 좋아진다.)
equals(), hashCode()와 HashMap의 관계
객체의 주소값이 달라도 객체의 값이 같으면 같은 객체로 판단하는 것을 동등성이라 한다.
아래의 동등한 객체 하나를 생성하여 두 인스턴스를 생성하고 p1를 맵에 추가하여 p2 인스턴스로 맵에서 데이터를 조회하는 코드를 보자.
class Person {
private String name;
private int age;
public Person(String name, int age) { /* 생략 */}
}
public class Main {
public static void main() {
Person p1 = new Person("Person", 20);
Person p2 = new Person("Person", 20);
Map<Person, String> map = new HashMap();
map.put(p1, "KO");
System.out.println(map.get(p2));
}
}
위의 결과는 null이다. 그 이유는 HashMap의 내부 동작 원리 때문이다.
HashMap은 찾고자 하는 데이터의 키를 hashCode()를 사용하여 해시코드를 알아내고 버킷을 찾은 후 equals()를 이용하여 동등성을 비교하여 데이터를 찾는다.
@Override
public boolean equals(Object o) {
if (this == o) return true;
// if (!(o instanceof Person)) return false; // 아래의 if문과 같은건가??
if (o == null || getClass() != o.getClass()) return false;
Person person = (Person) o;
return Objects.equals(this.name, person.name) && Objects.equals(this.age, person.age);
}
@Override
public int hashCode() {
final int prime = 31;
int result = 1;
result = prime * result + age;
result = prime * result + ((name == null) ? 0 : name.hashCode());
return result;
}
⚠ 오버라이딩시 클래스의 멤버변수 모두 equals()에서 비교해줘야 한다.
위 코드와 같이 equals()와 hashCode()를 오버라이딩을 해줘야 동등성을 가지게 되는데 둘 중 하나만 오버라이딩 한다면 동등성이 되지 않는다.
hashCode()는 해시코드로 버킷의 위치를 찾기 때문에 오버라이딩을 하지 않을 경우 두 Person 객체는 Map에서 size()가 2가 출력이된다.
equals()는 해시코드로 찾은 값으로 버킷에 있는 Entry(k, v)를 찾아 해당 객체의 값들을 비교하기 때문에 멤버변수 하나라도 참조하고 있는 주소가 다르다면 다른 객체로 간주한다.
따라서 반드시 두 메서드를 오버라이딩하여 Collection의 동등성을 지켜줘야 한다.